...turn up and down the volume while speaking in the way if I speak the volume of the desk goes down and when I stop talking the volume goes up again...
As an audio guy, that sounds like a ducker to me. You can make one from a compressor, by having it respond to a different signal than the one that it affects.
OBS has a compressor natively as one of the audio filters, so you can put it on your desk source or whatever else that you want to "duck" under your voice, and then put your voice in the Sidechain:
It'll behave a bit differently than the macro version. The most obvious way to me at the moment is that the macro always drops the background by a fixed amount (which might be what you want), whereas the compressor/ducker drops more if your voice is louder and less if you're softer.
And the macro only checks 10x per second or whatever you have it set to, whereas the audio filters check every sample. (44.1 or 48 thousand per second) Much more responsive that way.
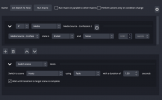
The amount that it drops is [volume - Threshold] x Ratio...except that the Ratio control is labelled differently, as the actual ratio of the change in input volume to the change in output volume. The two timing controls - Attack and Release - are basically fade times - one down and one up - and the Output Gain is simply a fixed volume control after everything else is done. (so instead of only turning it down, it can turn up by that much normally and reduce from there)
A limiter is simply a compressor with oo:1 Ratio. Dedicated ones often have non-adjustable instant Attack as well, and the Gain control moved to the input so that it acts *before* the Threshold. OBS's limiter only has Threshold and Release, so any pre-gain needs to be a separate filter.
The screenshot here is for a presentation mic, which is Behringer's clone of an SM58 a fair distance away in a makeshift studio. No settings for Noise Suppression. Limiter has a Threshold of -6dB and Release 100ms. The Compressor does most of the work, and the Limiter is more of a "safety net". A different rig (not here at the moment) has the same Compressor filter used as a ducker so that a remote meeting doesn't feed back through the mic to the remote people. Hearing yourself that much later completely throws off your concentration, so the local mic (quite drastically in this case) ducks under the remote participants.
--- Geeking out a bit: ---
Conceptually, you can think of the compressor as only turning things down, and then the Output Gain (or makeup gain) is a separate thing that follows that, but most compressors implement it as an offset to the control signal instead. Same effect. If I have a bunch of channels to mix together, like a band, I often use the compressors' makeup gains to trim the faders so that they all line up nicely for an "okay" mix. The faders then become offsets from that instead of absolute controls.
In an analog compressor, like you might find in a recording studio or "old school" live rig, you have a volume detector that produces a control signal, which is compared to the Threshold and the difference (or zero if negative) moves on. Then the timing controls slow down their respective edges, followed by a "volume control" of sorts that turns down the control signal (this is the Ratio: all the way up is oo:1, all the way down is 1:1 or no effect), and finally the Output Gain or Makeup Gain offsets the control signal before feeding it to the gain element. Increasing control signal turns the gain element down, by the same amount that the detector produced it. (so if you connected them directly together, you'd always get the same volume out regardless of anything, which would amplify the electronic noise of an otherwise silent input to that volume, hence the Threshold to avoid that)
So far, I've described a "feedforward" compressor, where the detector is up front, measuring the raw signal, and its result is fed "forward" in terms of signal flow to the gain element. This makes it easy to disconnect the detector from the original input and feed it something else instead, which makes it a ducker. Or (in the more free-form analog world, and the digital things that already thought of it) you could put an EQ or other processing before the detector so that it responds more to the boosted frequencies (turns them down more) and less to the rest. The side-chain jack outputs a copy of the raw input for that purpose, in addition to receiving what the detector should respond to. A switch in that jack automatically connects the detector to the input, when there's no plug present.
There are also "feedback" compressors, where the detector is on the output and fed "back" to the gain element that comes before. This can only be a compressor, not a ducker (I guess technically it *could*, but it would change to a feedforward ducker), and can't reach oo:1 ratio. They're fairly rare now...except that our ears work this way, using the auditory nerve signals as the detector and restricting the movement of the eardrum as the gain element. Thus, when old people say, "It's too loud," it's probably because they can't restrict their eardrums anymore, and so they really are getting blasted more than someone younger...and consequently lose more of their hearing while the younger one doesn't lose any.
The quality of the mix also makes a difference because our hearing is essentially an RTA or spectrum analyzer, not a single microphone, and the signal to "clamp down" is the average of that RTA. Thus, a small range of prominent frequencies keeps the average low, so we don't clamp down, which allows that small range to get blasted and possibly damaged. A good mix is more even in its frequency content, which brings the average up, so that we do clamp down and then we're okay...so long as we're still able to clamp down.